

Understanding physiology and neuroscience requires knowing a certain amount of biochemistry. Most of the building blocks of our bodies are macromolecules composed of proteins (long chains of amino acids), polysaccharides (carbohydrates), lipids (fats) and nucleic acids (which make up DNA and RNA).
Amino acids and proteins
Amino acids are the basic building blocks for proteins. In a way, they are quite simple, all being variations on the same basic formula.
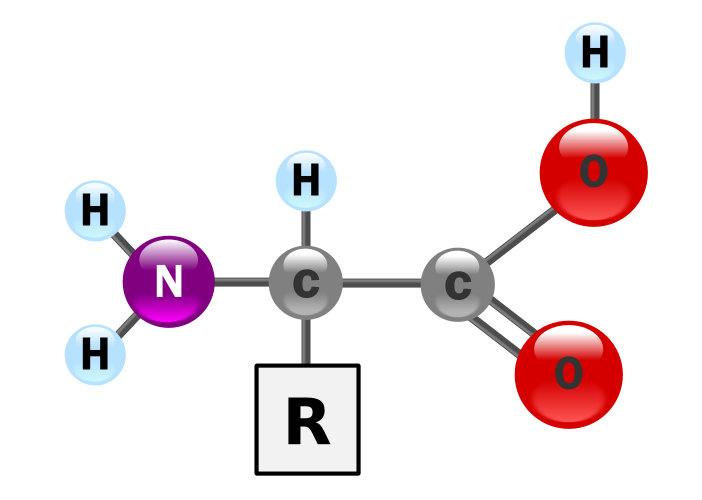
Common formula for amino acids, by “GyassineMrabetTalk” via Wikimedia Commons
Each amino acid consists of a central carbon atom, an amino group (NH3+), a carboxyl group (COO–) and a variable group, designated by the letter “R”, for residue. In the figure, the third H in NH3 has been transferred to one O on the COO– to make COOH and balance out the total charge.
The complete set of amino acids comprises only 21 acids and is shown in the following figure. It is often stated that there are only 20 amino acids, in which case selenocystein, which occurs rarely, has been omitted.
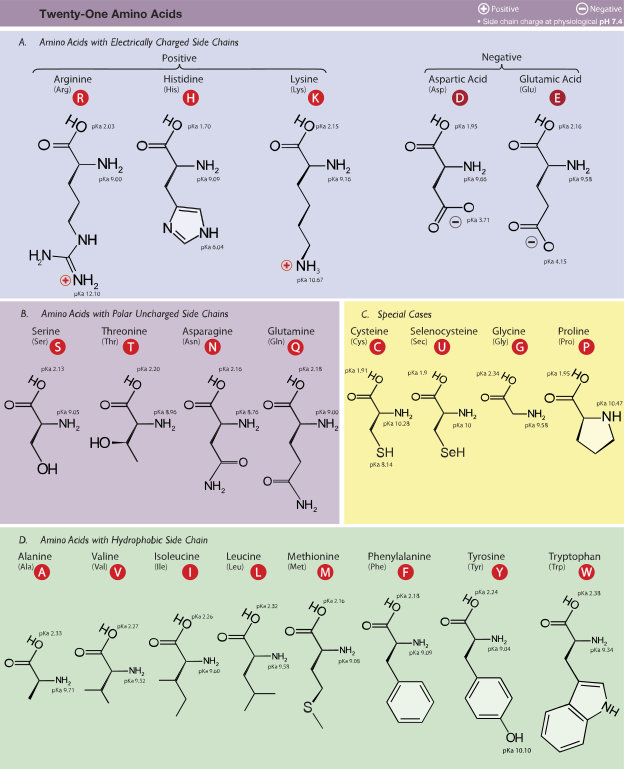
The amino acids, by Dan Cojocari via Wikimedia Commons
Amino acids are the basic building blocks of proteins. A protein is a polypeptide, that is a polymer (a chain of linked subunits) formed by condensation (ejection of water molecules) so as to link the amino acids by peptide bonds. Schematically, it looks like the example in the following figure, which shows the OH– on the left combining with an H+ on the right to make a water molecule and leave the two amino acids connected by a peptide bond. Actually, the process is not that direct, but goes through several enzyme-assisted steps in order to achieve the peptide bond. (We’ll get back to enzymes shortly.)
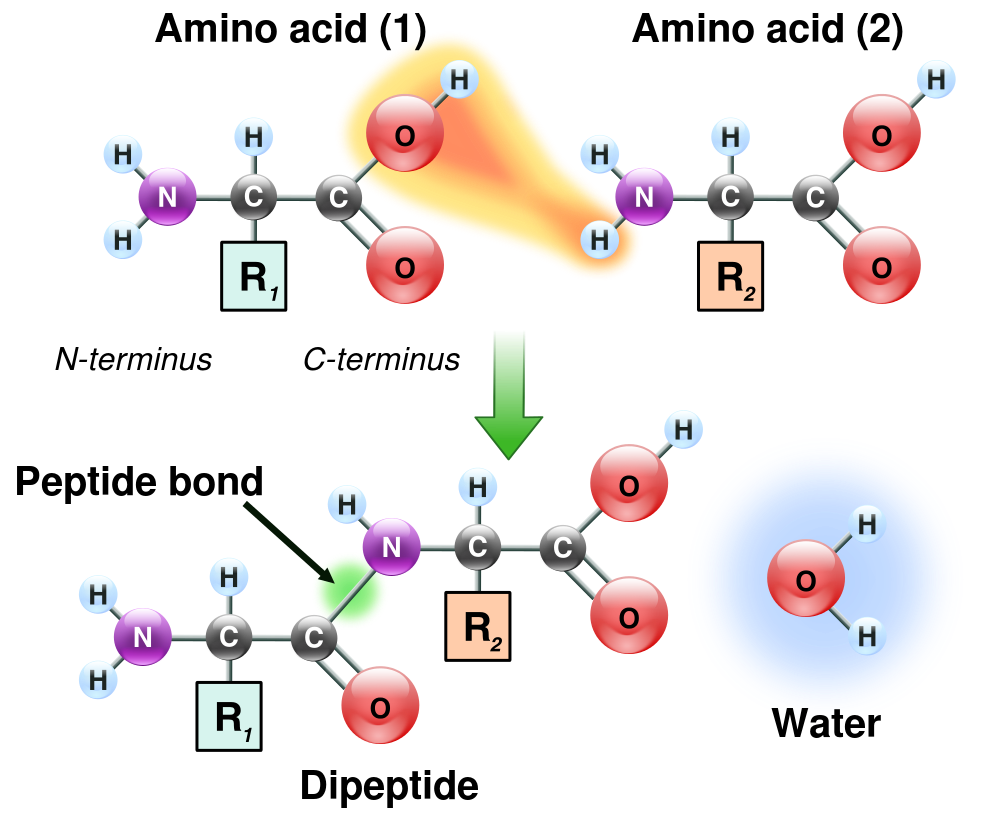
Peptide formation by condensation of two amino acids, by “GyassineMrabet” via Wikimedia Commons
The bonding properties of proteins depend largely on their shape. The shape of the protein depends first on the sequence of amino acids, which constitutes the protein’s primary structure. The polypeptide chain may then coil up into a secondary structure called the alpha helix. The R groups may interact among themselves, bringing about a change in the 3-dimensional shape, or conformation, the tertiary structure. Different polypeptide chains then may bind to form a quaternary structure. In this way, proteins can take on very intricate shapes.
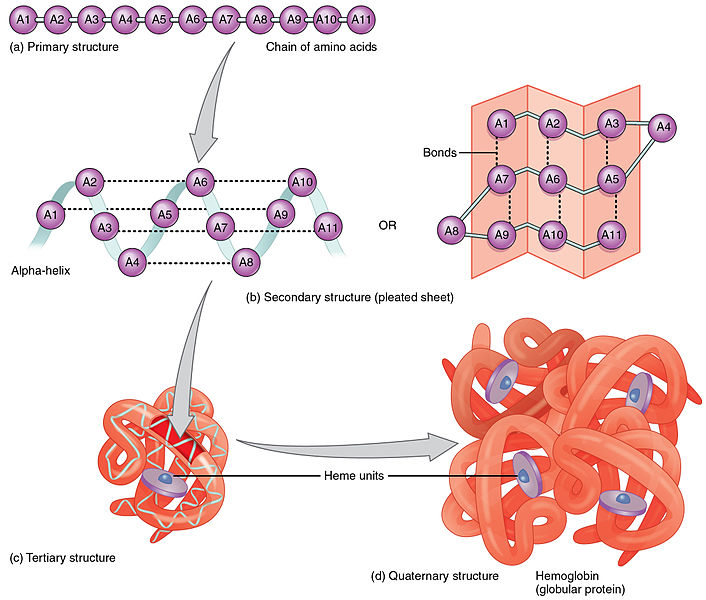
Four hierarchical structures of hemoglobin, by OpenStax College via Wikimedia Commons
Symmetry does not seem to be well respected in biology. A helical protein with a right-handed twist can not generally be substituted for one with a left-handed twist: It just will not work the same way. This differing of the two versions is called chirality.
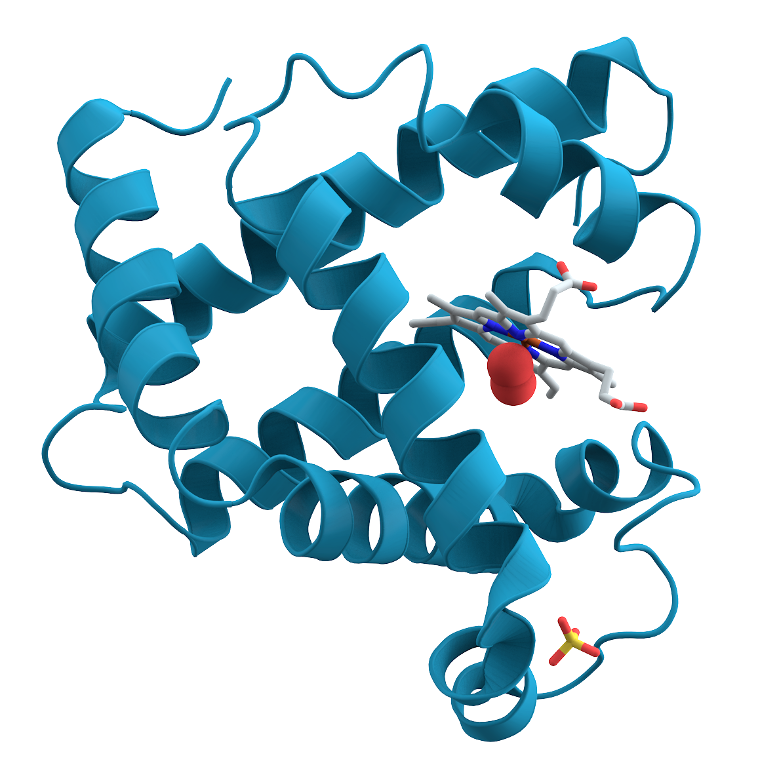
3D structure of myoglobin protein. Alpha helices are turquoise. By AzaToth via Wikimedia Commons
Proteins may be enormously long polypeptide chains.
Enzymes
Enzymes, which are usually proteins1RNA can also function as an enzyme and it is not a protein., serve as organic catalysts, meaning that they help to bring about reactions that otherwise would not happen or would happen far too slowly. They only bring about reactions which are energetically possible but which nevertheless need a “push” to get started. Enzymes provide the push by lowering the activation energy of the reaction. Complete equations for different reactions would include the enzymes on both sides, but they are usually omitted. Every physiological process in the body depends on enzymes. Enzymes themselves only work under rather strict conditions of temperature and acidity. If the pH or temperature is not just right, the enzymes will not work, the reactions will not take place and the organism will suffer. The names of enzymes generally end in -ase, for example, lactase.
An enzyme can do its work because of its shape. It folds itself so as to form a pocket called the active site. A molecule which fits into the active site is called a substrate. The enzyme can then usher the substrate through the reaction. This “lock and key” model of enzyme-subtrate interaction is refined further in the induced-fit model, wherein dynamic modifications in the enzyme’s structure enable It to exactly fit the substrate, like a glove stretching to fit a hand.
The body can regulate the rate of such reactions by regulating the efficiency of the enzymes which catalyze it. One way to do this is to have a molecule similar in shape to the substrate and use it to block the active site. Or a molecule can bind to what is called an allosteric site on the enzyme, meaning a site which is not the active site. Binding to such a site changes the shape of the molecule and thereby renders it ineffective for binding with its usual substrate. If the enzyme catalyzes a reaction too much, so that there is an excedent of end products, the end products themselves may attach to an allosteric site and block further reactions, resulting in a feedback mechanism which reduces the rate of the reaction.
Reactions catalyzed by enzymes generally take place in a number of small steps rather than all at once. This has a double advantage:
- At each step, the enzyme can bring the reactants together, reducing the activation energy, the amount of energy needed for the reaction to begin.
- The energy output from each small step will not be so much as to harm the cell.
The sum of all the small steps is referred to as a metabolic pathway.
Carbohydrates
Carbohydrates are molecules composed of carbon, hydrogen and oxygen, usually with the latter two elements in the same relative amounts as in water. So a generic “carb” could be represented by the formula
Cm(H2O)n
Carbohydrates are saccharides, or sugars, and referred to as monosaccharides or polysaccharides, depending on the length of the molecule.
The most important monosaccharides in the body are: two, ribose and deoxyribose, based on rings of five carbon atoms (pentoses) and three, glucose, fructose and galactose, based on rings of six carbon atoms (hexoses).2In fact, glucose, galactose and fructose all have the same formula, C6H12O6, but differ in their conformations. Similarly, ribose and deoxyribose share the same formula, C5H10O5, but different conformations.
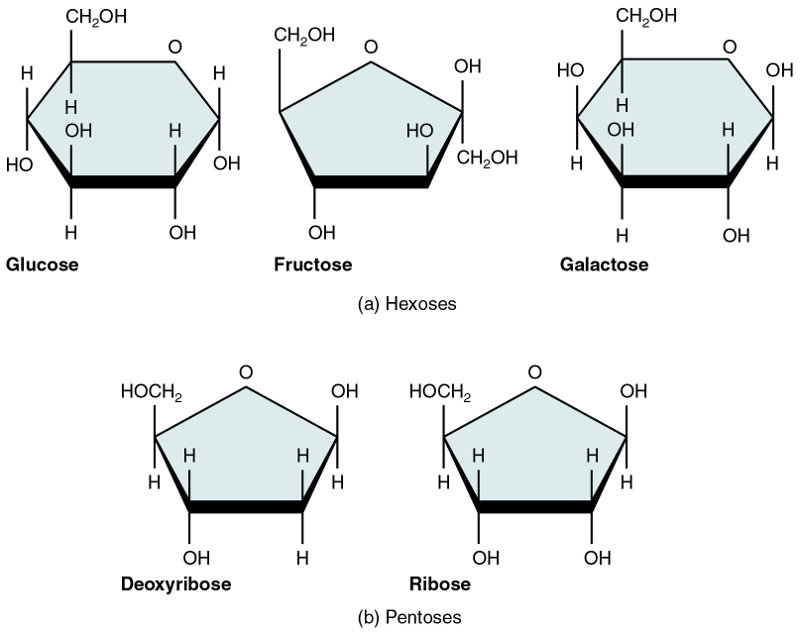
The five common monosaccharides, from Openstax College
Saccharides formed from two monosaccharides are called disaccharides. Important ones for the human body are sucrose (table sugar), lactose (milk sugar) and maltose (malt sugar).
Polysaccharides may contain thousands of monosaccharides. Common ones are starches (polymers of glucose found in plant foods), glycogen (a polymer of glucose used for storage in the body) and cellulose (“fiber”, found in the cell walls of plants).
We will be considering the importance of carbohydrates in the body’s production of energy from food.
Lipids
Lipids are mostly hydrocarbons with very little oxygen and so forming only non-polar C-C or C-H bonds, making them hydrophobic. They consist of triglycerides, phospholipids, cholesterol and small quantities of other substances. Lipids are necessary for the formation of cell membranes and for other functions within cells.
Trigylcerides
The commonest form of lipid (“fat”) in the body is triglyceride, consisting of a glycerol nucleus covalently bonded to the ends of three fatty-acid chains, long hydrocarbon chains terminated at one end by a carboxyl group (COO-) and at the other by a methyl group (CH3). The C=O link to the glycerol is an ester linkage.
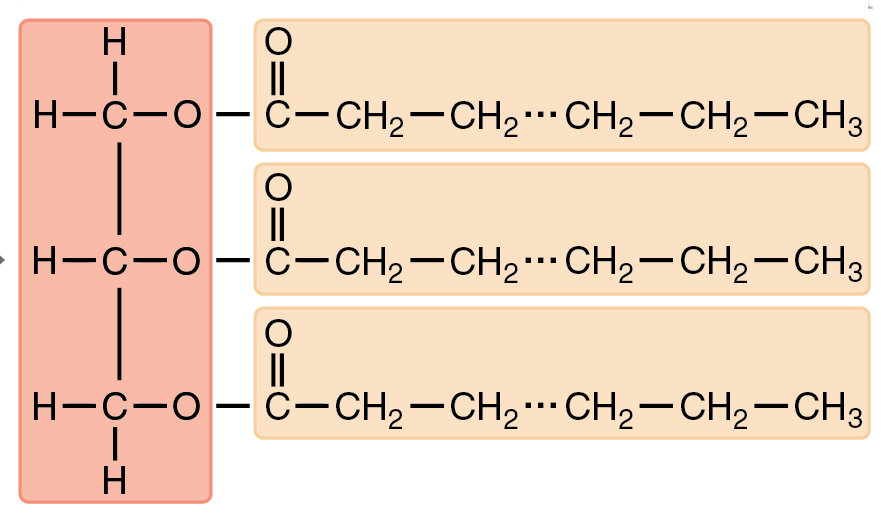
Triglyceride structure, with three fatty acids (orange background) attached to glycerol (pink), adapted from Openstax College
Fatty acids may be saturated or unsaturated, meaning saturated in bonds with hydrogen. A saturated fatty acid has only single bonds between carbon molecules, leaving two bonds free to connect with hydrogen. An unsaturated acid may have a double bond between carbons, meaning each one can only bond with one hydrogen. The double bonds between carbons may change the shape of the fatty acid.
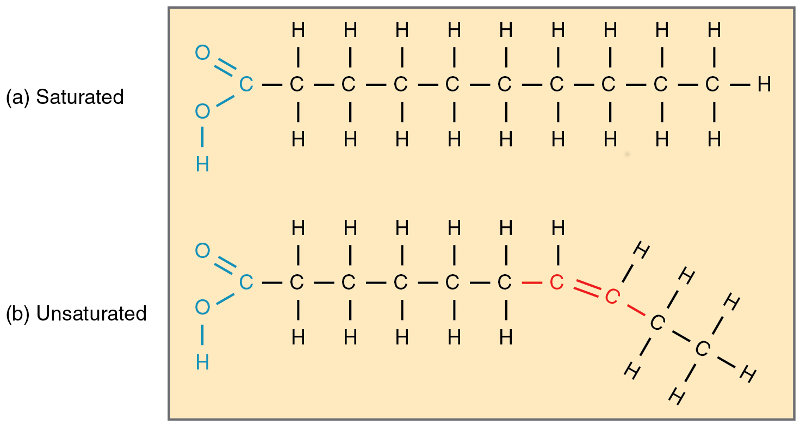
Saturated and unsaturated fatty acids, from Openstax college
Saturated fatty acids pack tighter and so exist generally as semi-solid substances called fats. Unsaturated fatty acids pack more loosely (because of the kinks) and are the constituents of more liquid oils
It is currently thought3Or, at least, recently. It’s hard to keep up with what nutritionists tell us. that saturated fats lead to increased risk of heart disease, relative to unsaturated fats. The worst, though, is thought to be so-called trans fats.4The word trans comes from biochemistry and indicates functional groups on opposite sides of the carbon chain. In order to ensure longer shelf life, food producers sometimes convert unsaturated fats into saturated ones by hydrogenation, the addition of hydrogen atoms5The first such hydrogenated shortening was marketed under the brand name Crisco. It was partially hydrogenated cottonseed oil.. Trans fats are those which have only been partially hydrogenated6In more detail, a cis double bond is converted to a trans double bond, hence the trans.. On the other hand, there is evidence that omega-3 unsaturated fats are effective in reducing the risk of heart disease and perhaps beneficial in other ways. They are called omega-3 because the word “omega” is used in biochemistry to refer to the methyl end of the fatty acid chain and the double carbon bond is the third from that end.
Phospholipids
Phospholipids are similar to triglycerides, but the glycerol is attached to only two fatty acids, the third being replaced by a “head group” containing phosphate.
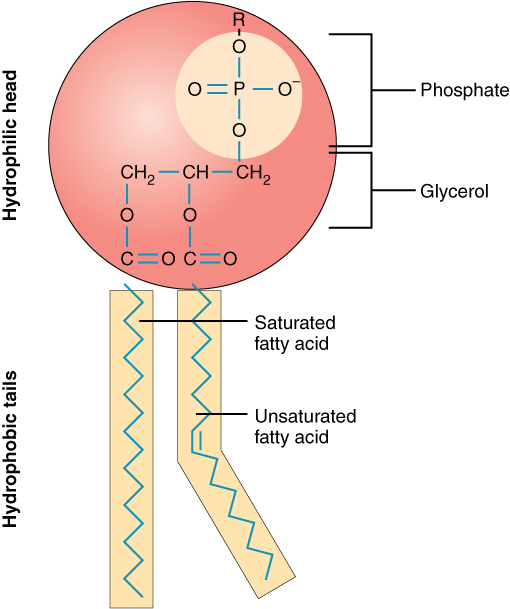
Phospholipid structure, from Openstax College, via Wikimedia Commons
The phosphate “head” is negatively charged and therefore hydrophilic but the fatty acid tails are hydrophobic, so the molecule is ampiphatic (as discussed in the chemistry chapter) and forms micelles or membranes in an aqueous environment. Of major importance for life, phospholipids are the principal component of cell membranes.
Nucleotides
Just as proteins are polymers formed from chains of amino acids, nucleic acids – DNA and RNA – are polymers made up of chains of linked nucleotides. A nucleotide is composed of a pentose (five-carbon) sugar molecule like deoxyribose (which gives the “D” in DNA) or ribose (in RNA), a nitrogenous base (or nucleobase) and one phosphate group.7Common usage employs the term nucleotide for those with more than one phosphate group. Different nucleotides contain different bases.
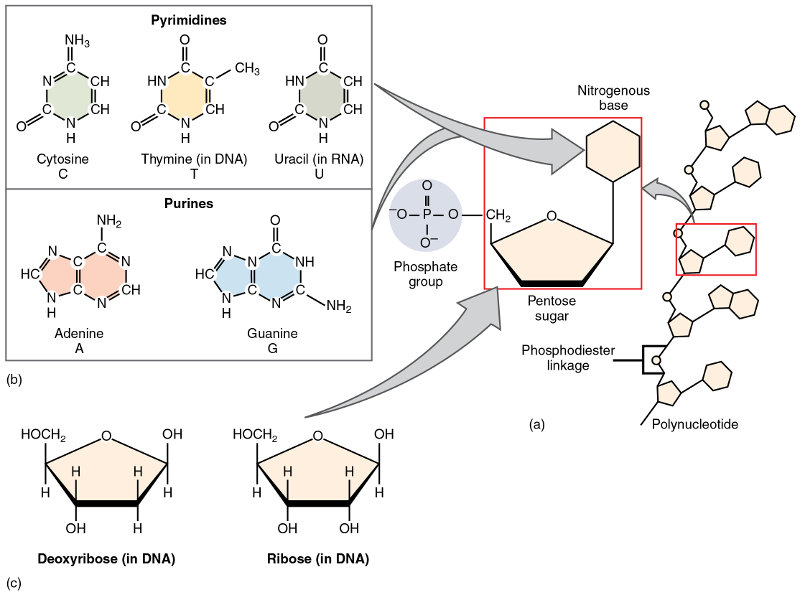
Nucleotides, from Openstax College
There are five possible nucleobases in two groups:
- pyrimidines – cytosine, thymine and uracil, with a single-ring structure; and
- purines – adenine and guanine, with two rings and therefore two nitrogen atoms.
Another, very special nucleotide is adenosine monophosphate, or AMP. When a second phosphate group is added to AMP, it makes ADP (adenosine diphosphate); addition of a third phosphate group makes adenosine triphosphate, or ATP, the “energy currency” or energy carrier in cells of all living organisms. Like all nucleotides, AMP consists of a nitrogenous base attached to a pentose sugar attached to a phosphate group; in this case, the nitrogenous base is adenine and the pentose sugar is ribose. It takes energy to add a Pi (phosphate) to make ADP or a Pi to ADP to make ATP. This energy is stored in the ATP molecule as chemical potential energy and can be recovered later to do useful biological work, such as to flex muscles (including heart muscles), make blood flow, power peristaltic movement of the intestines or permit action potentials in neurons. We will talk much more of this in the next chapter.
A nucleotide without the phosphate group is called a nucleoside, so ATP may also be referred to as a nucleoside triphosphate. Nucleoside triphosphates are the raw materials for building RNA molecules.
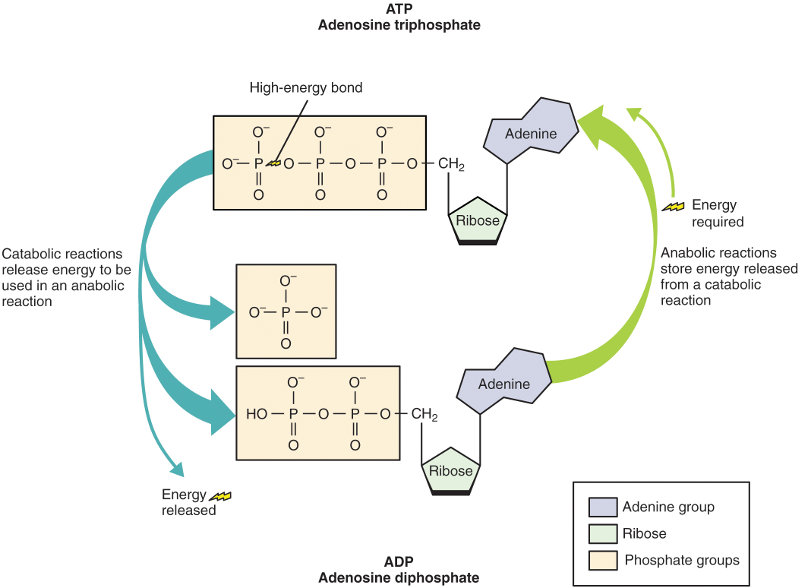
ATP and ADP, from Openstax College
Nucleic acids – DNA and RNA
The nucleic acids, DNA and RNA, are assembled from nucleotides. They differ in three ways:
- DNA, deoxyribonucleic acid, contains deoxyribose as its sugar; RNA, ribonucleic acid, contains ribose.
- The “allowed” nucleobases for DNA are cytosine (referred to in this context as C), guanine (G), adenine (A), and thymine (T); in RNA, T is replaced by uracil (U).
- DNA molecules form a double strand; RNA, a single one.
The IUPAC (International Union of Pure and Applied Chemistry) has a rather hairy set of rules for numbering carbon atoms in organic compounds. In the case of the sugar in a nucleotide, the 1′ carbon (one-prime, prime to denote sugar) is the one attached to the nitrogenous base. The count moves around the ring away from the oxygen apex.
Nucleic acids are formed by dehydration (or condensation, removal of a water molecule) between a pentose sugar of one molecule (the 3′ carbon) with the phosphate (on the 5′ carbon of the pentose) of another. The result is called a phosphodiester bond. The chain is thus held together by a sugar-phosphate backbone, independently of attached nucleobases, which protrude out from the chain.
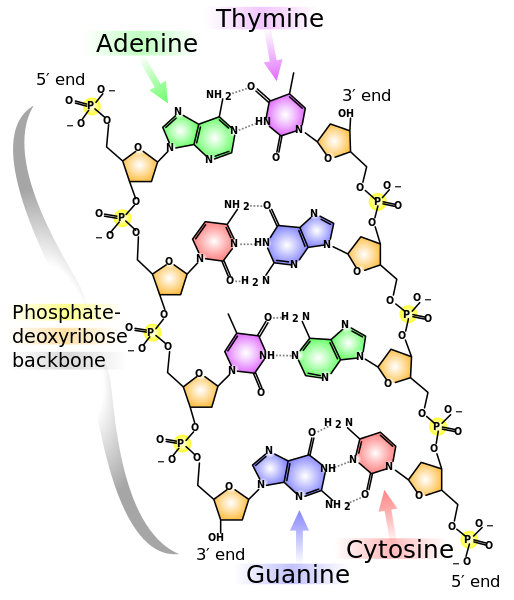
DNA chains form double strands due to hydrogen bonds between nucleobases on each chain, with C bonding only to G and A only to T. So a purine (A or G) is always bonded to a pyrimidine (C, T or U). The result forms a double helix, like a twisted ladder. Note from the preceding figure that there are three hydrogen bonds between guanine and cytosine, but only two between adenine and thymine.
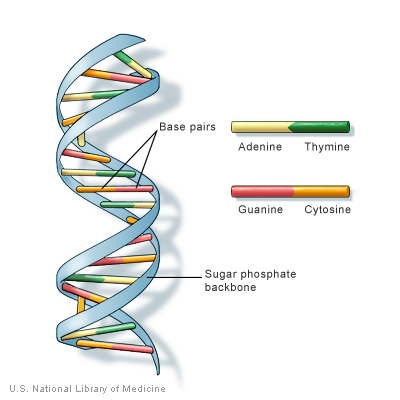
DNA structure, from U.S. National Library of Medicine
The combination of two DNA strands into a double helix offers the advantage that the nucleobases are not sticking out into the cytoplasm where they may be more easily mutated. Rather, the bases of the two strands are “holding hands” (through hydrogen bonds) to protect each other from mutation. This increased security may explain why DNA, which stores genetic information, forms a double helix, but RNA does not.
Some detail: The nucleic acid strand is polar, i.e., the ends are not the same. One end has a phosphate group attached to the 5′ carbon of the sugar; this is called the 5′ end. The other end has a hydroxyl group (OH–) attached to the 3′ carbon of the sugar, so this is called the 3′ end. When combining into a double helix, the ends are reversed, i.e., the 3′ end of one is opposite the 5′ end of the other.
Since the total length of all the DNA strands in a human nucleus would equal 2-3 m, it must be compacted in order to fit into the nucleus. The helical strand is wrapped around histone proteins to form nucleosomes. The string of nucleosomes is then twisted and re-twisted, like a piece of cord, until it forms a compact string called chromatin. The chromatin will be used to form chromosomes (only) when needed for reproduction.
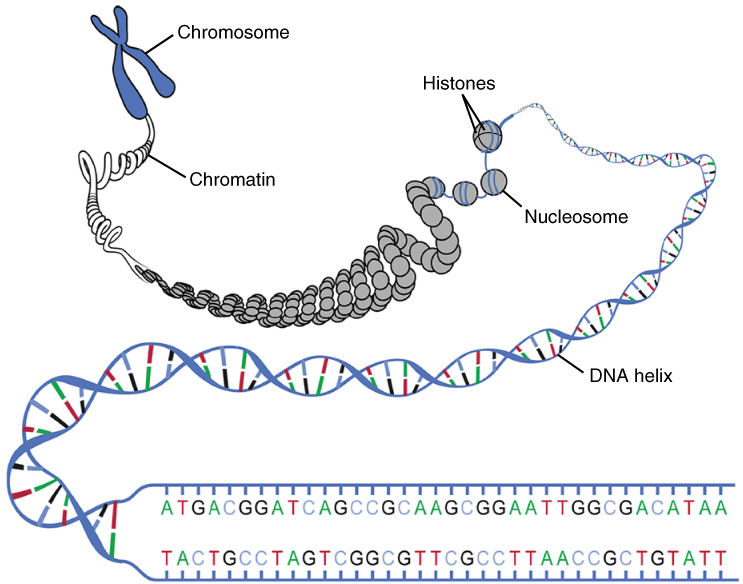
DNA compaction, from Openstax College
Oxidation-reduction and electron carriers
The concept of oxidation and reduction is essential to biochemistry, so let’s beat on it a while. Actually, it also is important to other domains of chemistry. Oxidation and reduction occur together in oxidation-reduction, or redox, reactions.
An entity which loses electrons is said to be oxidized; if it gains electrons, it is reduced. Think of its charge, which becomes more negative as it gains an electron. Oxygen likes to gain electrons, so when it pinches one from another substance, that substance is oxidized. A simple example is Na and Cl going together:
Na + Cl → Na+ + Cl–
The Na loses an electron and becomes positive; it is an electron donor and is oxidized. The Cl gains an electron, becoming negative, and is reduced.
A substance which is oxidized, i.e., gives up electrons, is an electron donor or reducing agent or reductant. One which is reduced, i.e., gains electrons, is an electron receptor or oxidizing agent or oxidant. Schematically, we can write
donor (reductant) <—> e- + electron receptor (oxidant)
where the reductant and oxidant together are said to constitute a conjugate redox pair.
The term oxidation is understood perhaps most clearly in a reaction like the rusting (oxidation) of copper:
2 Cu + O2 → 2 CuO
One can see that:
- At the same time as oxygen receives electrons from Cu and so is reduced,
- copper, in releasing electrons to oxygen, adds on oxygen to become copper oxide (rust).
So we can see that adding oxygen is also oxidation and releasing it is reduction.
Again,
H2 + F2 → 2 HF
which is perhaps not easy to recognize as an oxidation of hydrogen. But consider the two half-reactions, the obvious oxidation part
H2 → 2 H+ + 2 e–
and the reduction part
F2 + 2 e– → 2 F–
Put them together to get
H2 + F2 → 2 H+ + 2 F– → 2 HF
But now, look at combustion (oxidation) of propane. It can be complete combustion
C3H8 + 5 O2 → 3 CO2 + 4 H2O
or partial combusion
C3H8 + 2 O2 → 3 C + 4 H2O.
Carbon is obviously oxidized in complete combustion, since it adds oxygen. Partial combustion, even though it does not add oxygen, is still considered oxidation. So we can add:
- Releasing hydrogen is also a sign of oxidation.
It’s inverse therefore must be reduction.
A less obvious example is oxidation of copper oxide:
2 Cu2O + O2 → 4CuO.
The thing to notice here is that the first oxide of copper is cuprous oxide, where copper has a valency state of +1. On the right, though, it has valency state of +2 and so this is cupric oxide. Copper has changed valency states and In so doing has given up an electron, which indicates oxidation.
Chemists also talk about oxidation-reduction in term of oxidation states, but those are complicated too, so we will ignore them. Finally oxidation-reduction criteria can bet represented in the following table.
| redox process | electron | oxygen | hydrogen |
| oxidation | release | add | release |
| reduction | add | release | add |
Getting back to biochemistry, more interesting examples, which are important in cellular respiration, are those of the coenzymes8A coenzyme is a non-protein compound that is necessary for the functioning of an enzyme. Enzymes are macromolecular catalysts, most of which are proteins. nicotinamide adenine dinucleotide and flavin adenine dinucleotide, better and more simply known as NAD and FAD. These two molecules are electron carriers and they pick up and leave off their electrons through redox reactions. If a reaction such as
C6H12O6 + 6O2 → 6CO2 + 6H2O
is allowed to take place all at once, it releases a useless and dangerous amount of energy. So the reaction is broken up into intermediate steps with these cofactors as intermediate oxidizing and reducing substances. Their oxidized forms are NAD+ and FAD and they are reduced to NADH and FADH2.
NAD is a dinucleotide, meaning it is composed of two nucleotides, which are joined by a phosphate group. One nucleotide has an adenine base, the other, nicotinamide.
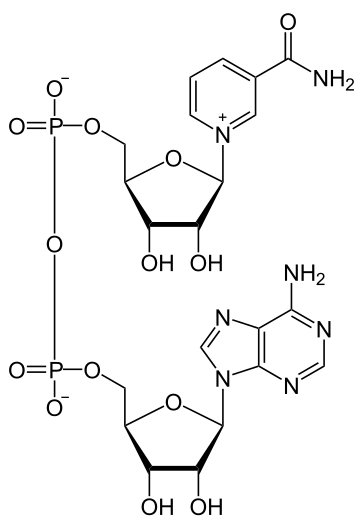
NAD molecule by “NEUROtiker” via Wikimedia Commons
During cellular respiration (explained later), a molecule referred to as the substrate gives up two H atoms, and so is oxidized, bringing about the reduction of NAD+ in the following way, where R means “residue” and indicates a substrate:
RH2 + NAD+ → NADH + H+ + R
Ignoring R on both sides
NAD+ + 2H → NADH + H+
or, in more detail,
NAD+ + 2H → NAD+ + H– + H+ → NADH + H+
which shows that one of the H atoms is in the form of hydride, H–, with two electrons.The NAD+ absorbs the hydride, equivalent to two electrons electrons and one proton, thereby gaining electrons and so being reduced to NADH. (Remember, NAD+ and NADH are abbreviations, not chemical forumulas.) In a later step, both the H atoms will be used for energy transfer and the NADH will give up two electrons and so be re-oxidized to NAD+. In this way, NAD transports electrons from one reaction to another.

NAD oxidation-reduction by Fvasconcelllos via Wikimedia Commons
The equivalent formula for the reduction of FAD goes in two steps:
FAD + e– + H+ → FADH
FADH + e– + H+ → FADH2
to make
FAD + 2H → FAD + H– + H+ → FADH2
which shows that FAD is reduced to FADH2 since it adds both electrons and hydrogen.
Now we are ready to look at cells, the basic units of life.
Notes
| ↑1 | RNA can also function as an enzyme and it is not a protein. |
|---|---|
| ↑2 | In fact, glucose, galactose and fructose all have the same formula, C6H12O6, but differ in their conformations. Similarly, ribose and deoxyribose share the same formula, C5H10O5, but different conformations. |
| ↑3 | Or, at least, recently. It’s hard to keep up with what nutritionists tell us. |
| ↑4 | The word trans comes from biochemistry and indicates functional groups on opposite sides of the carbon chain. |
| ↑5 | The first such hydrogenated shortening was marketed under the brand name Crisco. It was partially hydrogenated cottonseed oil. |
| ↑6 | In more detail, a cis double bond is converted to a trans double bond, hence the trans. |
| ↑7 | Common usage employs the term nucleotide for those with more than one phosphate group. |
| ↑8 | A coenzyme is a non-protein compound that is necessary for the functioning of an enzyme. Enzymes are macromolecular catalysts, most of which are proteins. |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}